Basic primitives, Queues, Thread pools
This is an introductory task where we touch on the concept of thread pool, the core component for scheduling and executing work in our distributed file system. Backend systems communicate by sending and receiving messages, upon receiving a message the system typically runs some work. Modern hardware trending to scale much more through support of multiple cores rather than growing frequency of individual computation units.
CPU Scaling Trends
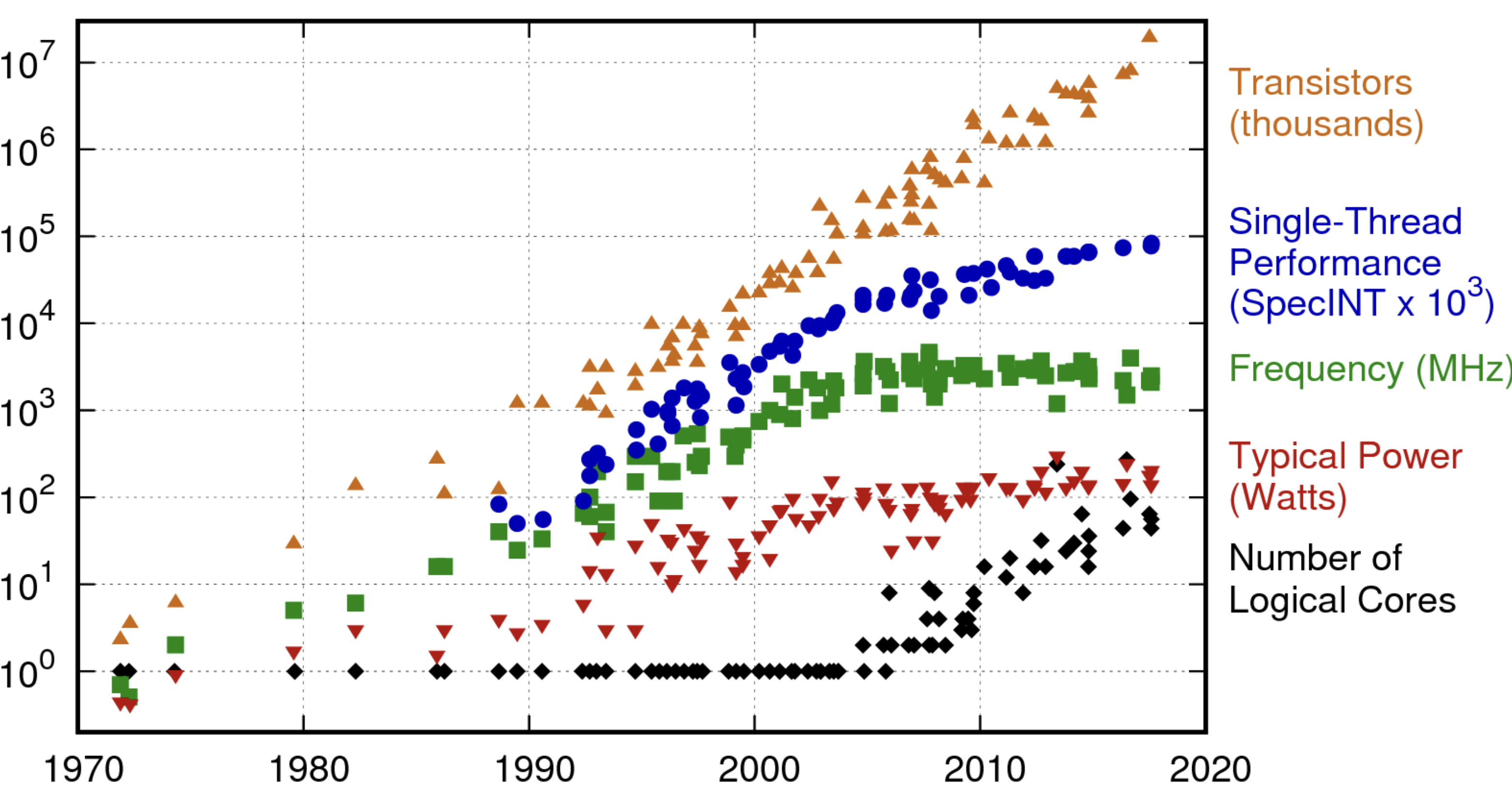
To utilize the full capacity of the hardware we will run those callbacks on multiple cores / threads by scheduling them on the thread pool. For further task the thread pool will serve as a main infrastructure component for scheduling and executing work in parallel.
Reusing Resources
A thread pool is a programming concept that pre-allocates a set of reusable worker threads to execute tasks. Instead of creating a new thread for every task, the thread pool manages a queue of incoming tasks and assigns them to available threads, avoiding the overhead of frequent thread creation. Thread creation is a resource-intensive operation, consuming time and memory, especially when dealing with a high volume of tasks. By reusing threads, the thread pool reduces these costs and ensures efficient use of CPU and memory resources.
Common implementations of thread pools include JVM's ExecutorService, Python's concurrent.futures.ThreadPoolExecutor, and C++'s Folly executors.
There are multiple scheduling algorithms to organize work in the thread pool such as FIFO, Work Stealing, etc. In this task you're suggested to implement the straightforward approach with a single shared queue for distributing load across multiple threads.
Sample thread pool (green boxes) with waiting tasks (blue) and completed tasks (yellow)
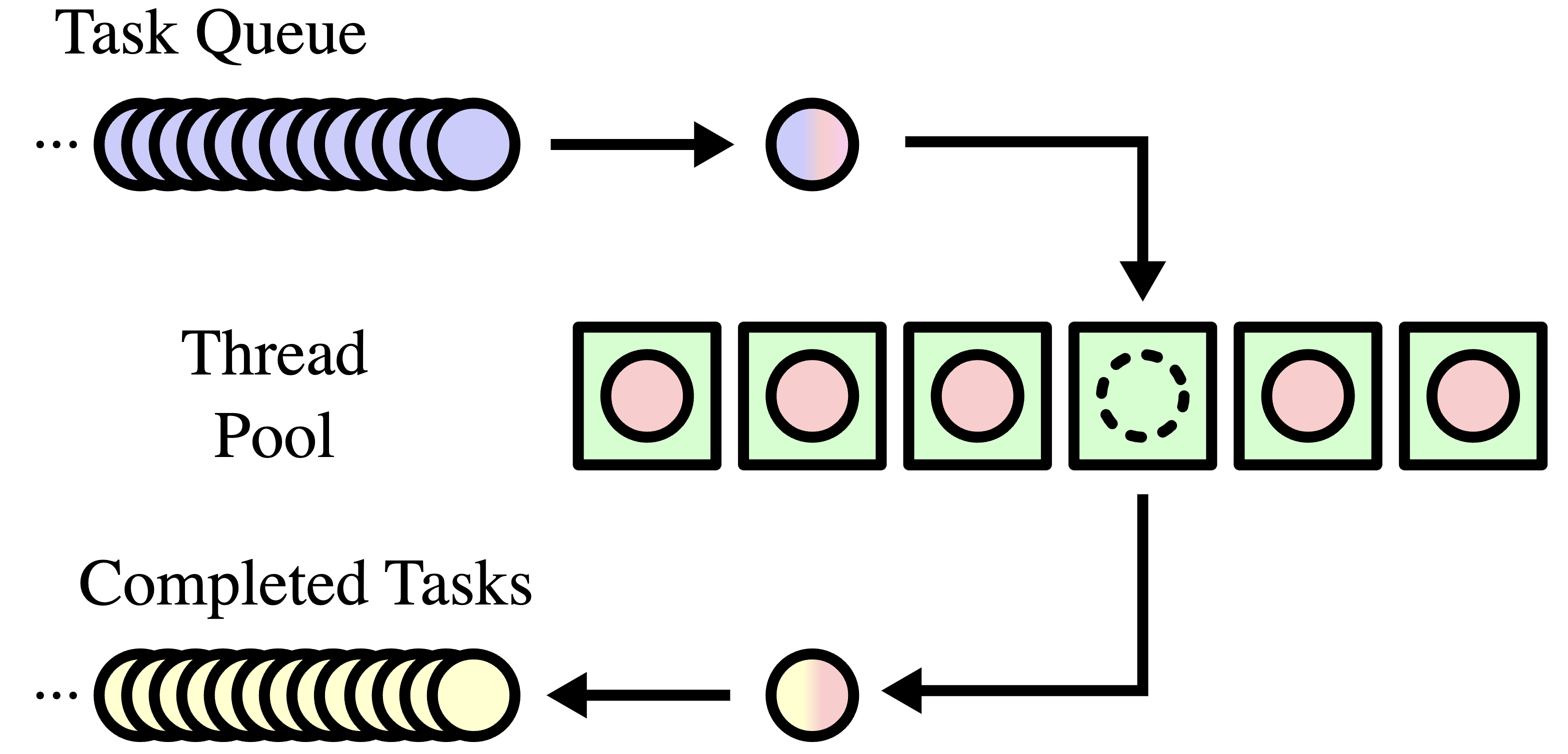
High-level Interface
The main method of the ThreadPool is submit which adds the task to the queue, and returns control back to the caller. Methods start and stop are there for managing lifecycle of the pool and self-explanatory:
using Task = std::function<void()>;
// Fixed-size pool of worker threads
class ThreadPool {
public:
explicit ThreadPool(size_t threads);
void start();
bool submit(Task&&);
void stop();
}
Queue
Our thread pool implementation will rely on a shared queue. Callers can add tasks to the queue using the submit method, while worker threads monitor the queue and pick up new tasks once they complete their current ones. But what happens when there’s no work available for a thread?
There are several strategies to handle this. One approach is to continuously retry, checking the queue until work appears. However, this can be inefficient, as it wastes CPU cycles on idle polling without providing any value. A more efficient alternative is to "park" the thread, taking it off the CPU until new tasks are available.
// Unbounded blocking multi-producers/multi-consumers (MPMC) queue
template<typename T>
class UnboundedBlockingQueue {
public:
void put(T v);
T take(); // This will block if queue is empty
}
The thread pool will rely on UnboundedBlockingQueue.
🧠 Task
- You're given a naive implementation of
UnboundedBlockingQueuequeue withtakeimplementing a busy wait strategy, replace it with appropriate wait strategy without burning CPU cycles. - Implement
ThreadPoolclass.
Verification
Tests are located in thread_pool_test.cpp